 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving Dictionary Representation for Few-shot Class-incremental Learning
May 03, 2023New objects are continuously emerging in the dynamically changing world and a real-world artificial intelligence system should be capable of continual and effectual adaptation to new emerging classes without forgetting old ones. In view of this, in this paper we tackle a challenging and practical continual learning scenario named few-shot class-incremental learning (FSCIL), in which labeled data are given for classes in a base session but very limited labeled instances are available for new incremental classes. To address this problem, we propose a novel and succinct approach by introducing deep dictionary learning which is a hybrid learning architecture that combines dictionary learning and visual representation learning to provide a better space for characterizing different classes. We simultaneously optimize the dictionary and the feature extraction backbone in the base session, while only finetune the dictionary in the incremental session for adaptation to novel classes, which can alleviate the forgetting on base classes compared to finetuning the entire model. To further facilitate future adaptation, we also incorporate multiple pseudo classes into the base session training so that certain space projected by dictionary can be reserved for future new concepts. The extensive experimental results on CIFAR100, miniImageNet and CUB200 validate the effectiveness of our approach compared to other SOTA methods.
Contrastive Continual Learning with Feature Propagation
Dec 03, 2021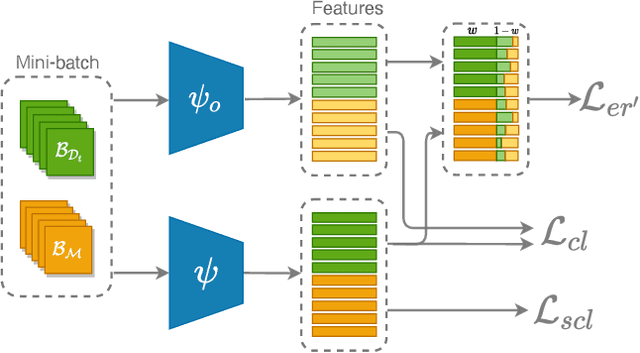
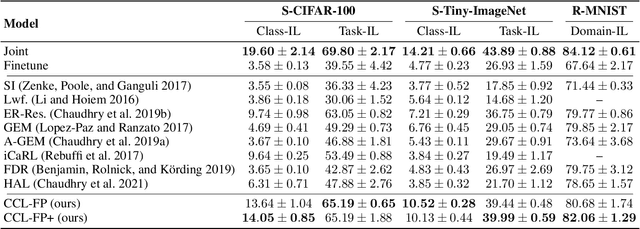
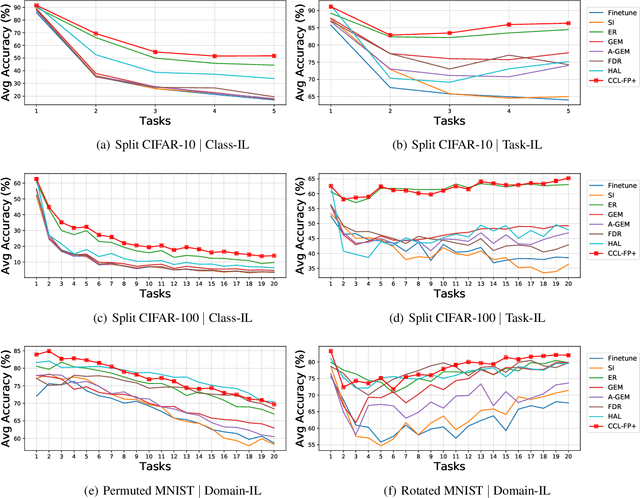
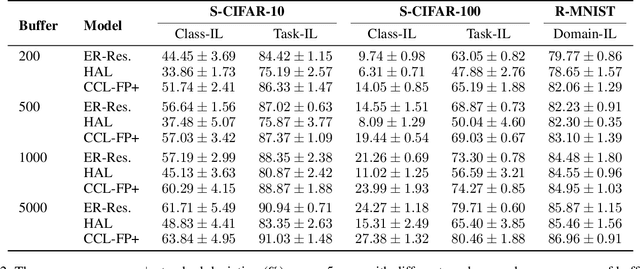
Classical machine learners are designed only to tackle one task without capability of adopting new emerging tasks or classes whereas such capacity is more practical and human-like in the real world. To address this shortcoming, continual machine learners are elaborated to commendably learn a stream of tasks with domain and class shifts among different tasks. In this paper, we propose a general feature-propagation based contrastive continual learning method which is capable of handling multiple continual learning scenarios. Specifically, we align the current and previous representation spaces by means of feature propagation and contrastive representation learning to bridge the domain shifts among distinct tasks. To further mitigate the class-wise shifts of the feature representation, a supervised contrastive loss is exploited to make the example embeddings of the same class closer than those of different classes. The extensive experimental results demonstrate the outstanding performance of the proposed method on six continual learning benchmarks compared to a group of cutting-edge continual learning methods.